
Resampling: Die Häufigkeit macht den Unterschied
Wir haben im heutigen Interview mit KI-Experte Martin Schiele, Geschäftsführer der AI-UI GmbH an das Thema Data Scaling angeknüpft. Heute dreht sich alles um Resampling – Methoden. Erfahren Sie, was die typischen Verfahren ausmacht, wie sie funktionieren und wo sie in der Praxis Anwendung finden.
Was bedeutet Resampling?
Resampling bedeutet auf Deutsch Stichprobenwiederholung und bezeichnet die Bestimmung der statistischen Eigenschaften von Stichprobenfunktionen. Wurden Daten skaliert, wie in Blog V beschrieben, geht es im Maschinellen Lernen direkt im Anschluss oft darum, die Daten auszugleichen. Wir kennen das von uns selbst. Das, was wir am häufigsten tun, können wir in der Regel am besten und genau so lernt auch eine KI. Am Beispiel von Bildern zu Hunden und Katzen lässt sich das gut erklären. Stellen Sie sich vor, Sie haben ich nur 100 Katzenbilder, aber 10.000 Hundebilder, um einer KI beizubringen, die beiden Tiere zu unterscheiden. Wenn Sie den Datensatz unbearbeitet nutzen, dann wird die KI viel besser darin sein, Hunde zu erkennen als Katzen. Das liegt daran, dass die KI 100-mal mehr Bilder von Hunden sah (im Training) als Bilder von Katzen.
Und welche Methoden gibt es, um dem vorzubeugen?
Die zwei einfachsten und bekanntesten Methoden nennen sich „Undersampling“ und „Oversampling“. Mit Ihnen passt man Datensätze so an, dass die KI bei jedem Training die gleiche Anzahl an Klassen oder Werten sieht, ohne das eine häufiger vorkommt als die andere.
Dafür ist es notwendig zu verstehen, wie ein Histogramm funktioniert. Es zeigt einem, wie oft ein bestimmter Wert im Datensatz vorkommt. Im Bild rechts sehen Sie, dass im gegebenen Datensatz drei verschiedene Sorten von Orchideen unterschiedlich oft vorkommen. Setosa 40 mal, Versicolor 50 mal und Virginica 20 mal.
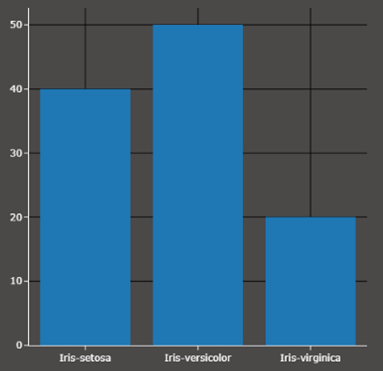
Wie funktioniert nun Undersampling?
Undersampling ist vergleichbar mit zufälligem Abschneiden. Man hat einen Datensatz und möchte irgendeinen Wert oder eine Klasse, in diesem Fall alle Klassen gleichförmig oft, vorkommen lassen. Dabei werden aus den Klassen, die öfter vorkommen (Setosa und Versicolor) als die am wenigsten auftretende (Virginica), zufällig Beispiele behalten und alle anderen gelöscht. Das führt dazu, dass Beispiele verloren gehen.
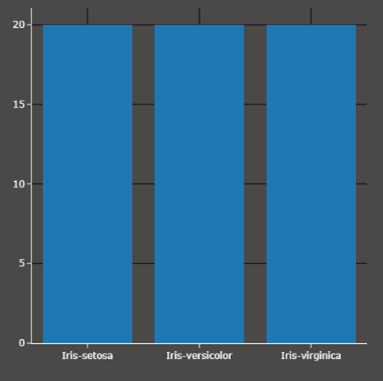
Wie funktioniert Oversampling im Gegensatz dazu?
Das Oversampling funktioniert genau andersherum. Wir versuchen die fehlenden Beispiele „einfach aufzufüllen“. Man nimmt also von Setosa beispielsweise zufällig 10 Beispiele aus den 40 vorhandenen und steckt sie erneut in das Dataset, sodass es 50 sind. Dabei gibt es natürlich mehrere doppelt. Genau so verfahren wir in diesem Beispiel mit Virginica. Aus 20 wird 50, was bedeutet, dass es hier Beispiele mindestens 3 Mal gibt. In jedem Falle aber ist das Datenset bezüglich der Orchideenklasse nun gleich verteilt!
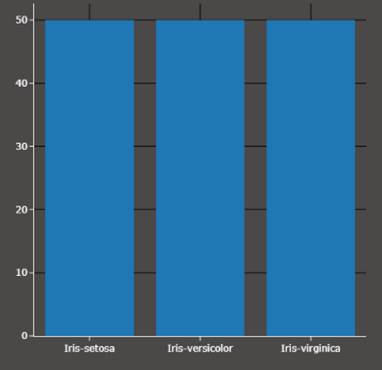
Was ist ein typischer Anwendungsfall?
Typische Anwendungsfälle sind überall zu finden, wo man keinen sogenannten „Bias“ (dt. Verzerrung) möchte. Ein Beispiel ist das Training eines Modells zur Vorhersage von Kriminalstatistiken mit personenbezogenen Informationen wie Alter, Herkunft und Familienstand.
Wenn schon im Datensatz ein altersbezogenes Bias enthalten ist, also das feature (dt. Merkmal), dass eine Altersgruppe einseitig überrepräsentiert ist, dann wird auch das Modell zukünftig eher dazu tendieren, die überrepräsentierte Klasse in den zukünftigen Vorhersagen öfter abzubilden. Ähnlich wie bei uns Menschen, schließen wir auf eine Ereignis-Eintrittswahrscheinlichkeit aus Erfahrung. Dies nennen wir auch Vorurteile, da sie oft nur in beschränktem Rahmen und subjektiv erfahren wurden.
Wir werden genau das im nächsten Blog anhand einer Bildklassifikation einmal demonstrieren. Dabei wird gezeigt, wie ein Modell reagiert, wenn es nur wenige Beispiele einer Klasse gesehen hat im Vergleich zu einem gleichverteilten Trainingsdatensatz anhand handgeschriebener Ziffern.
Wo kann AI-UI helfen?


