
Data Scaling: Bessere KI-Modelle durch einheitliche Daten
Es ist wieder so weit. Wir haben das nächste Interview mit KI-Experte Martin Schiele, Geschäftsführer der AI-UI GmbH geführt. Im heutigen Gespräch geht um das Thema Data Scaling. Wir haben mit Herrn Schiele zuerst einmal die Basis geklärt, was eigentlich Skalierbarkeit bedeutet. Wie sollte mit Daten umgegangen werden und warum muss man Daten überhaupt skalieren? Wir zeigen Ihnen einen Überblick, welche Methoden existieren, um Daten zu skalieren. Zum Abschluss zeigen wir auch ein Beispiel.
Was bedeutet Skalierbarkeit?
Skalierbarkeit bedeutet im Unternehmenskontext, dass man ein Geschäftsmodell hat, welches mit wenig Aufwand gut wachsen kann. Im Datenkontext bedeutet es die Möglichkeit der systematischen Werteveränderung. Es ist so ähnlich wie Prozentrechnung. Man sagt, das Auto hat 30.000 € UVP, es gibt 10% Rabatt und damit kostet es nur noch 27.000 €. Dabei skalieren wir automatisch die 30.000 € auf den Wert 100 (Einheit ist %) und ziehen einen vergleichbar großen Teil der Menge „10“ (in %) ab. Dann rechnen wir wieder um und kommen auf 27.000 €. Bei der Prozentrechnung skalieren wir sämtliche Daten um uns herum ständig.
Wie geht ein Unternehmen mit Daten um?
Häufig eher stiefmütterlich. Selbst wenn Daten erhoben werden, gibt es selten ein nachvollziehbares und zukunftsgerichtetes Ablagesystem, da es dem Unternehmen erst einmal nichts bringt außer Arbeit. Erst wenn es in diesen Daten einen Weg sieht, um Geld zu sparen, wird man sie auch als wertvoll einstufen. Ziel ist es also, tiefe Unternehmenseinblicke zu gewinnen.
Warum müssen Datensätze denn skaliert werden?
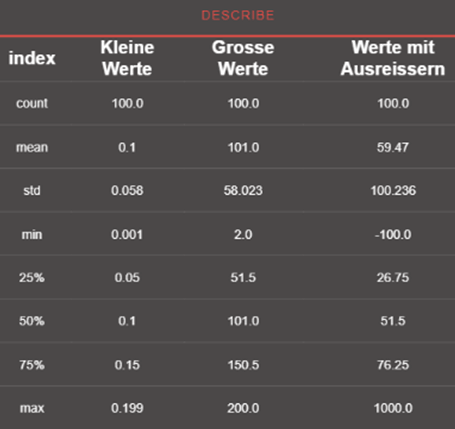
Stellen Sie sich vor, Sie hätten eine Datentabelle mit verschiedenen Spalten (links). Eine Spalte enthält kleine Werte, eine weitere viel Größere (Faktor 10.000 gegenüber der kleinen Werte) und eine dazwischen mit „Ausreißern“. Rechts sehen sie die statistische Auswertung. Es sind je 100 Werte pro Spalte.
Nehmen wir an, diese Werte beschreiben Insekten. Jede Zeile ein anderes Insekt. Kleine Werte stehen für die Augengröße in Metern. Große Werte für das Gewicht in Milligramm und „Werte mit Ausreißern“ für die Beinlänge in Millimetern. Es gibt hunderttausende verschiedene Arten, mit ganz unterschiedlichen Eigenschaften und jede Zeile steht für ein Tier. Als Ziel könnte man definieren, eine KI zu trainieren, die anhand dieser drei Werte klassifiziert, welcher Art das Insekt angehört.
Welche Methoden lassen sich anwenden, um Daten zu skalieren?
Es gibt viele Möglichkeiten, aber wir schauen uns im Folgenden drei sehr bekannte und im Bereich des Maschinellen Lernens genutzte Methoden an. Sie sind mit Programmierkenntnissen in der Python-Bibliothek Scikit-Learn zu finden und lauten: MinMax-Scaler, Robust-Scaler und Standard-Scaler. Alle drei skalieren auf unterschiedliche Weise. Die folgende Tabelle illustriert, für welche Probleme diese Skalieralgorithmen verwendet werden sollten:
| Name | Verteilung | Mittelwert | Wann nutzen? | Beschreibung |
|---|---|---|---|---|
| MinMax | Gebunden | Variiert | Immer! Erst wenn es nicht funktioniert, andere probieren. | Für jeden Wert in einer Spalte subtrahiert MinMax den Minimalwert und dividiert dann durch den Gesamtbereich. Der Bereich ist die Differenz zwischen dem ursprünglichen Maximum und dem ursprünglichen Minimum. |
| Robust | Ungebunden | Variiert | Verwenden, wenn Sie Ausreißer haben und nicht möchten, dass diese einen großen Einfluss nehmen. | Robust transformiert die Spalte durch Subtraktion des Medians und anschließende Division durch den Interquartilsbereich (75 %-Wert – 25 %-Wert ist Standard, lässt sich aber ändern). |
| Standard | Elementen-abweichung | 0 | Wenn ein Merkmal transformiert werden muss, damit es annähernd normalverteilt ist. | Standard skaliert eine Spalte durch Subtraktion des Mittelwerts und anschließende Skalierung auf Einheitsvarianz. Einheitsvarianz bedeutet, dass alle Werte durch die Standardabweichung geteilt werden. |
Könnten Sie ein einfaches, praktisches Beispiel zeigen?
Im Folgenden werde ich die oben gezeigte Tabelle in einem Box Plot jeweils vor und nach dem Skalieren, mit den dazugehörigen Einstellungen zeigen. So wird klar, wie sich die Daten mit den unterschiedlichen Wertebereichen verändern.
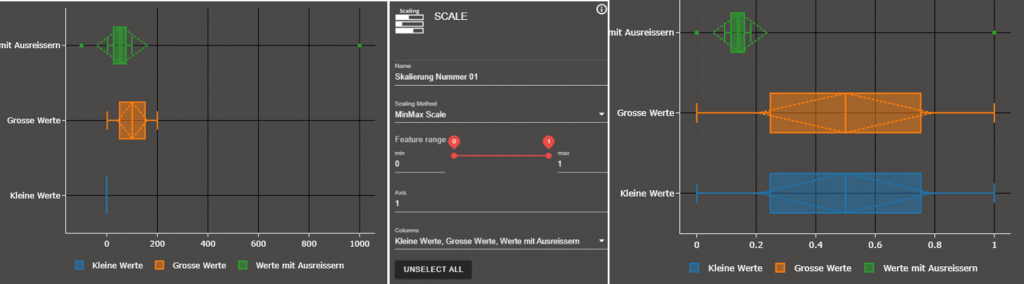
Im Bild links ist die ursprüngliche Verteilung zu sehen. Aufgrund zweier Ausreißer in der Spalte „mit Ausreißern“ also Beinlänge, liegt der Wertebereich auf der X-Achse zwischen -100 und 1.000. Also alle Insekten liegen eigentlich bezüglich der Beinlänge im Bereich 0 bis 100, aber 2 Tiere tanzen völlig aus der Reihe. Der Wert -100 muss wahrscheinlich sogar falsch sein, da Insekten keine negativen Beinlängen haben können. Jetzt kann man also die Zeilen mit den Ausreißern löschen, oder Sie doch mit einbeziehen, weil sie tatsächlich stimmen. Im Folgenden gehen wir einfach davon aus, dass die Daten OK sind. Skaliert man MinMax zwischen 0 und 1 wird wie bei dem Prozentrechnungsbeispiel für jede Spalte eine Umrechnung durchgeführt. Nun sind auch die „Kleinen Werte“ nicht mehr nur als Strich dargestellt, sondern erstrecken sich komplett innerhalb ihres Bereichs von 0 bis 1. Hier wird aber schon klar, was Ausreißer tun. Sie können zu Fehlabbildungen führen, denn dieses eine Beispiel mit dem Wert 1.000 ist womöglich nicht repräsentativ für den Rest des Datensets.
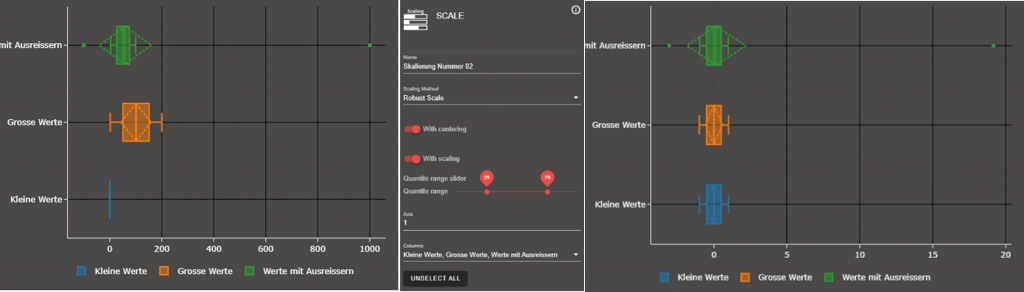
Robust wirkt dem entgegen. Durch die Auswahl von With Centering ist es zusätzlich möglich, den Mittelwert auf 0 umzurechnen, bevor in der Interquartile Range skaliert wird. Es ist festzustellen, dass Robust nicht die Ausreißer entfernt, sondern sie lediglich nur nicht bei der Berechnung des Mittelwertes und der Standardabweichung berücksichtigt.
Auch hier wurde wieder „zentriert“, dann aber durch die Einheitsvarianz geteilt.
Was ist ein typischer Anwendungsfall?
Typische Anwendungsfälle sind überall zu finden, wo man keinen sogenannten „Bias“ (dt. Verzerrung) möchte. Ein Beispiel ist das Training eines Modells zur Vorhersage von Kriminalstatistiken mit personenbezogenen Informationen wie Alter, Herkunft und Familienstand.
Wenn schon im Datensatz ein altersbezogenes Bias enthalten ist, also das feature (dt. Merkmal), dass eine Altersgruppe einseitig überrepräsentiert ist, dann wird auch das Modell zukünftig eher dazu tendieren, die überrepräsentierte Klasse in den zukünftigen Vorhersagen öfter abzubilden. Ähnlich wie bei uns Menschen, schließen wir auf eine Ereignis-Eintrittswahrscheinlichkeit aus Erfahrung. Dies nennen wir auch Vorurteile, da sie oft nur in beschränktem Rahmen und subjektiv erfahren wurden.
Wir werden genau das im nächsten Blog anhand einer Bildklassifikation einmal demonstrieren. Dabei wird gezeigt, wie ein Modell reagiert, wenn es nur wenige Beispiele einer Klasse gesehen hat im Vergleich zu einem gleichverteilten Trainingsdatensatz anhand handgeschriebener Ziffern.
Wo kann AI-UI helfen?


